



The semantic image segmentation task presents a trade-off between test time accuracy and training-time annotation cost. Detailed per-pixel annotations enable training accurate models but are very time-consuming to obtain; image-level class labels are an order of magnitude cheaper but result in less accurate models. We take a natural step from image-level annotation towards stronger supervision: we ask annotators to point to an object if one exists. We incorporate this point supervision along with a novel objectness potential in the training loss function of a CNN model. Experimental results on the PASCAL VOC 2012 benchmark reveal that the combined effect of point-level supervision and objectness potential yields an improvement of 12.9% mIOU over image-level supervision. Further, we demonstrate that models trained with point-level supervision are more accurate than models trained with image-level, squiggle-level or full supervision given a fixed annotation budget.
-
title={{What's the Point: Semantic Segmentation with Point Supervision}},
author={Amy Bearman and Olga Russakovsky and Vittorio Ferrari and Li Fei-Fei},
journal={ECCV},
year={2016}
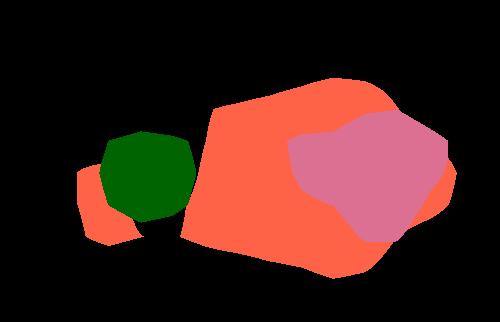
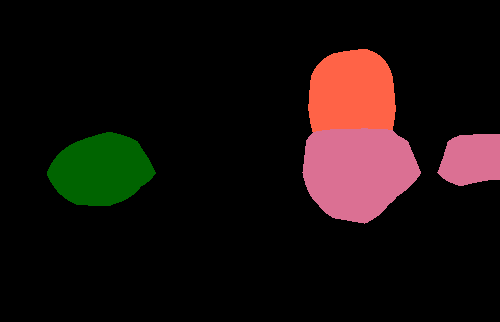
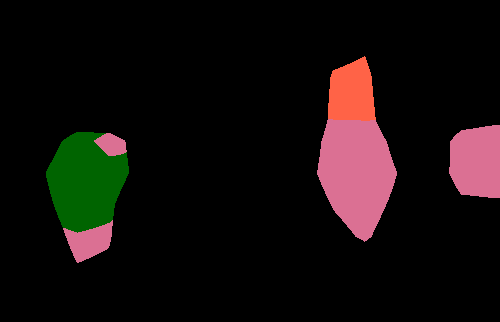
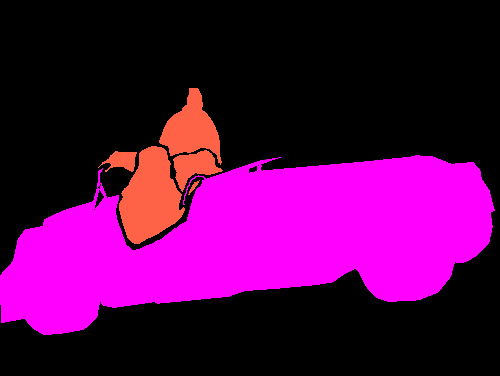
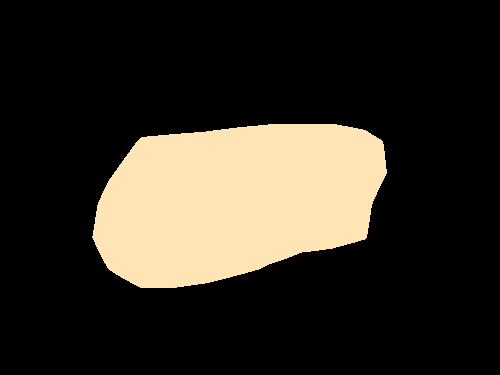
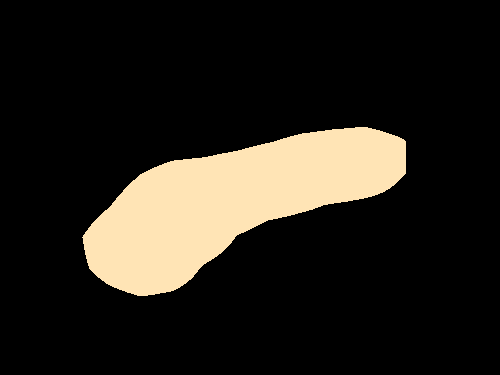
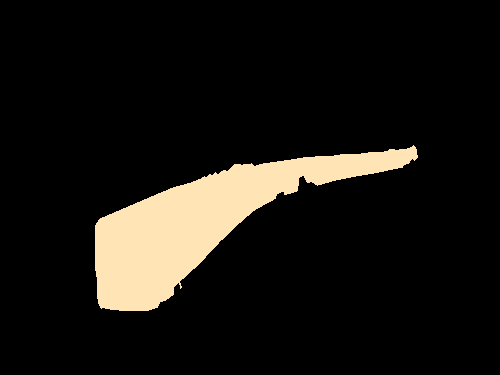
Semantic segmentation results on the PASCAL VOC 2012 validation set. The image-level CNN model (Img) is trained with only binary object class labels and no object location information. The objectness prior (Img + Obj) improves the accuracy of the image-level model (Img) by helping to infer the object extent. Point-level supervision (Img + Obj + 1Point) adds one supervised training pixel for each object class. It yields substantial improvements in test accuracy at small additional training annotation cost.
| Original image |
Img | Img + Obj | Img + Obj + 1Point |
Fully supervised |
Ground truth |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
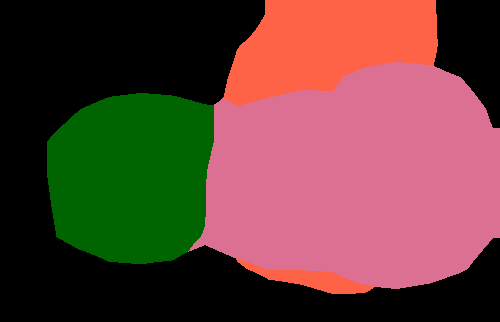 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |