|
||||||||||||||||||||||||||||
Given an image, we propose a hierarchical generative
model that classifies the overall scene, recognizes and segments
each object component, as well as annotates the image
with a list of tags. To our knowledge, this is the first
model that performs all three tasks in one coherent framework.
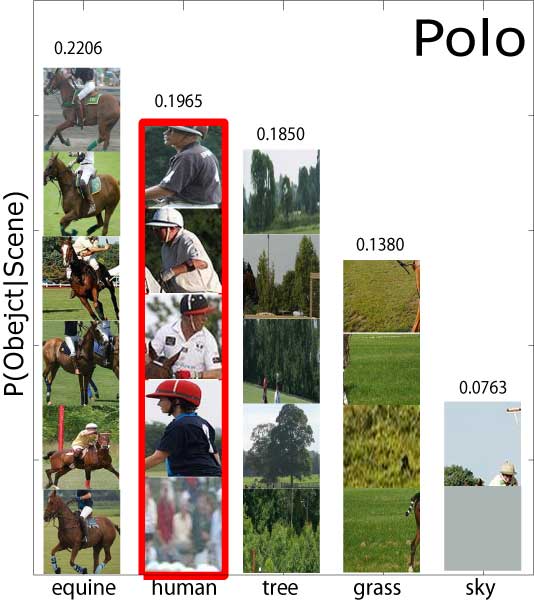
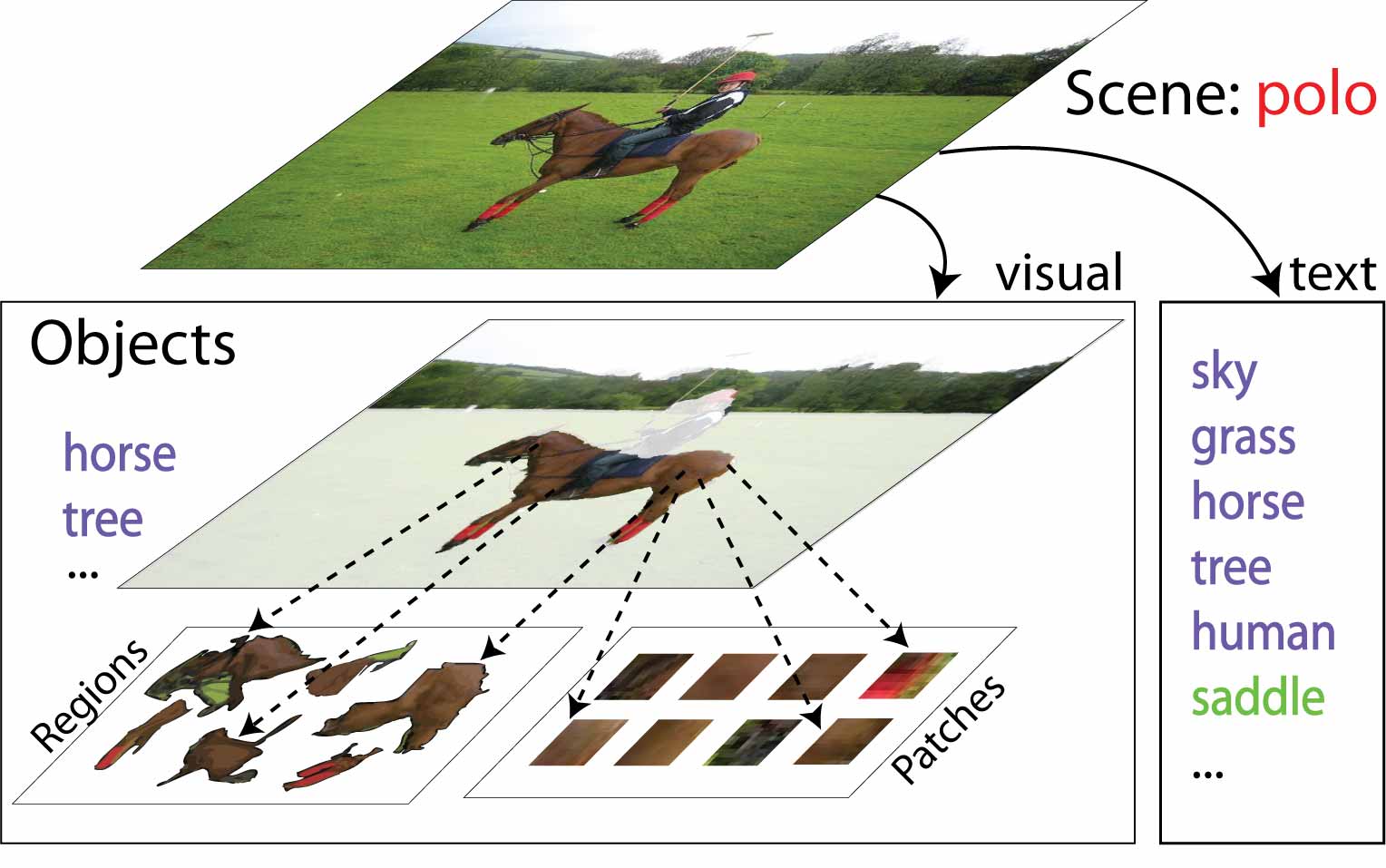
For instance, a scene of a ‘polo game’ consists of
several visual objects such as ‘human’, ‘horse’, ‘grass’, etc.
In addition, it can be further annotated with a list of more
abstract (e.g. ‘dusk’) or visually less salient (e.g. ‘saddle’)
tags. Our generative model jointly explains images through
a visual model and a textual model. Visually relevant objects
are represented by regions and patches, while visually
irrelevant textual annotations are influenced directly
by the overall scene class. We propose a fully automatic
learning framework that is able to learn robust scene models
from noisy web data such as images and user tags from
Flickr.com. We demonstrate the effectiveness of our framework
by automatically classifying, annotating and segmenting
images from eight classes depicting sport scenes. In
all three tasks, our model significantly outperforms state-of-
the-art algorithms. |
||||||||||||||||||||||||||||
Coherent Model back to top |
||||||||||||||||||||||||||||
 |
||||||||||||||||||||||||||||
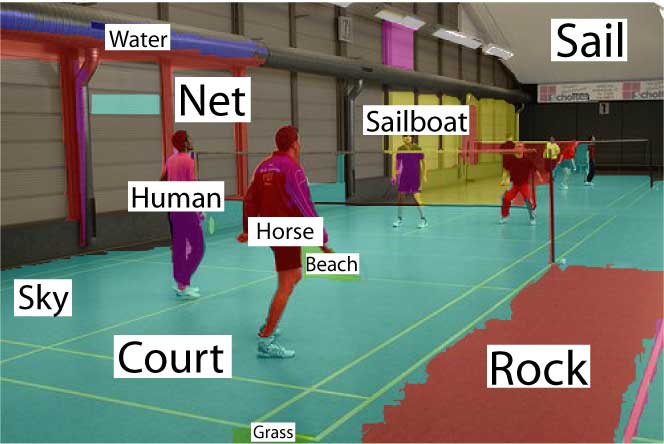
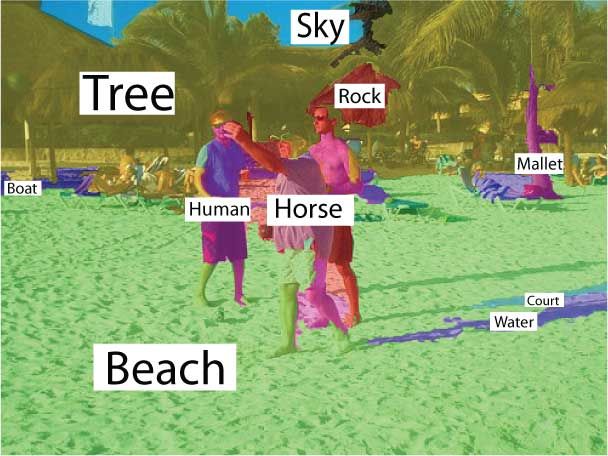
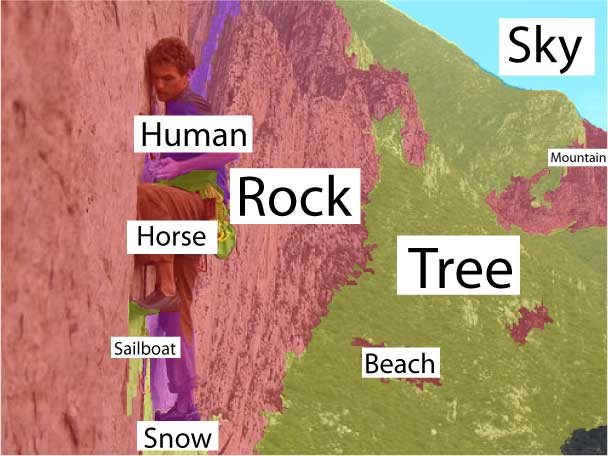
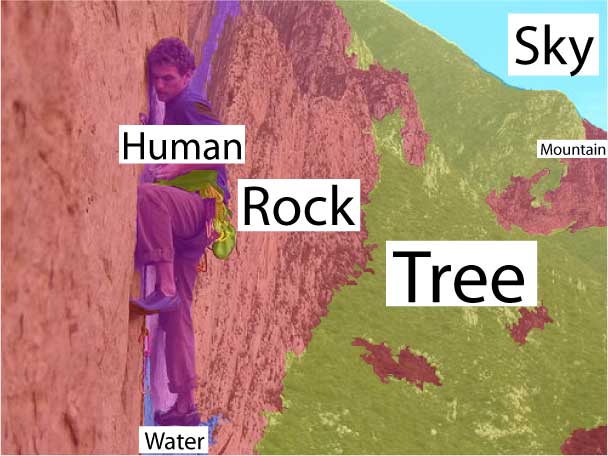
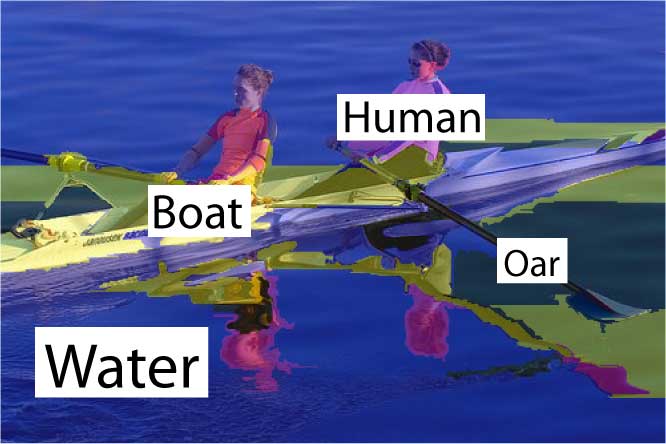
Our
model can recognize and segment multiple objects as well
as classify scenes in one coherent framework. |
||||||||||||||||||||||||||||
Automatic Framework back to top |
||||||||||||||||||||||||||||
 |
||||||||||||||||||||||||||||
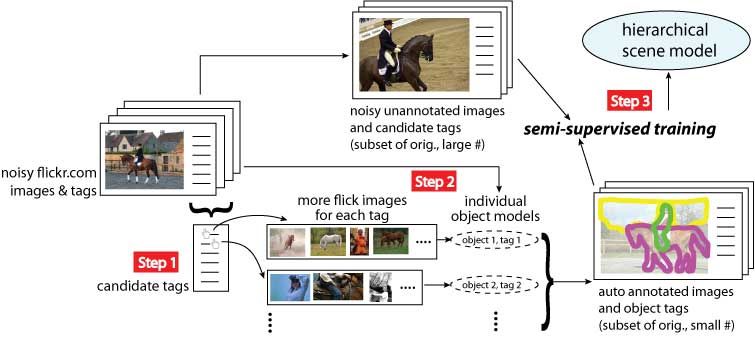
We propose a
framework for automatic learning from Internet images and
tags (i.e. flickr.com), hence offering a scalable approach
with no additional human labor. |
||||||||||||||||||||||||||||
Evaluation back to top |
||||||||||||||||||||||||||||
| Classification back to top | ||||||||||||||||||||||||||||
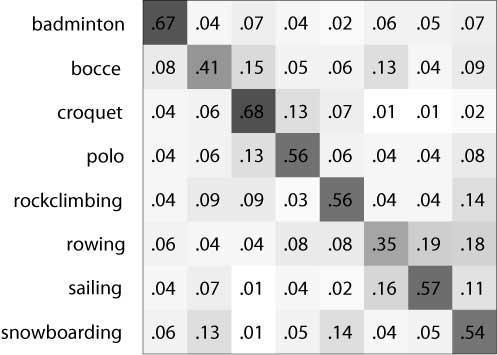 |
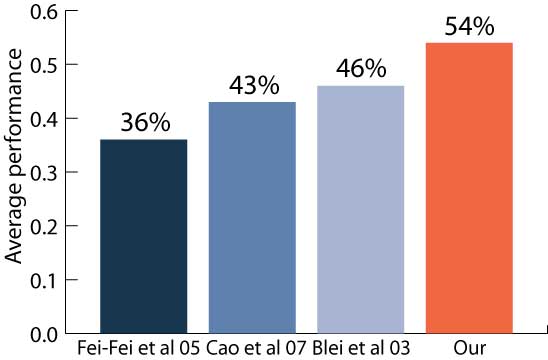 |
|||||||||||||||||||||||||||
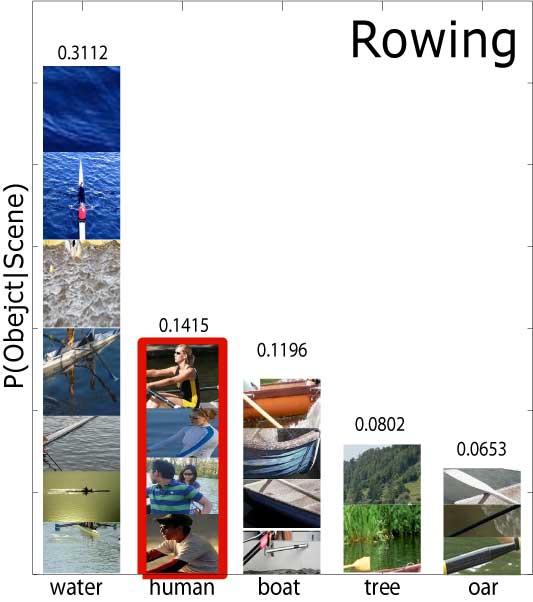
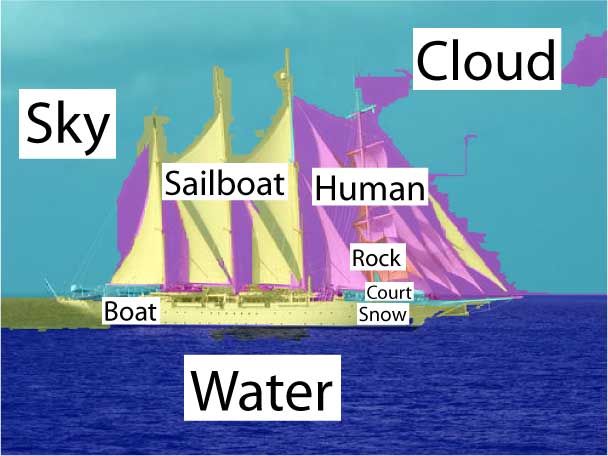
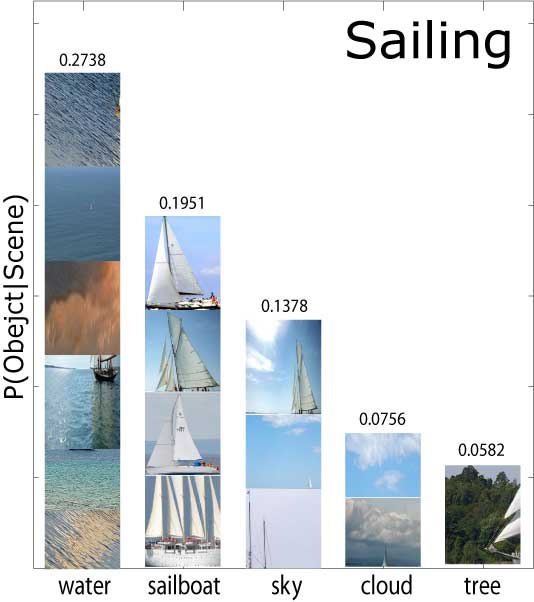
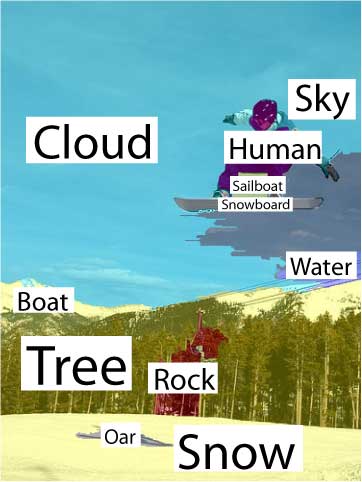
| Segmentation & Annotation back to top | ||||||||||||||||||||||||||||
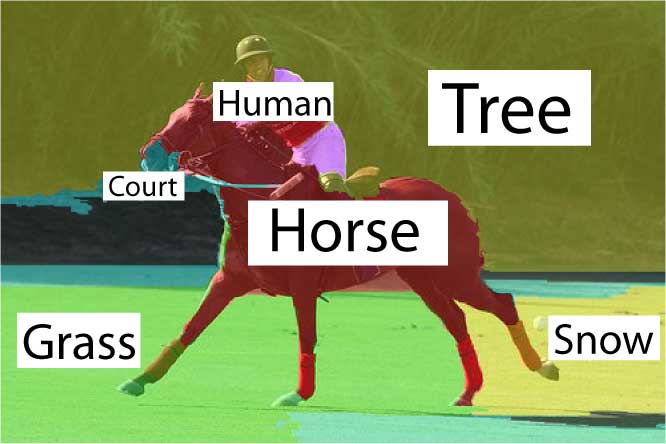
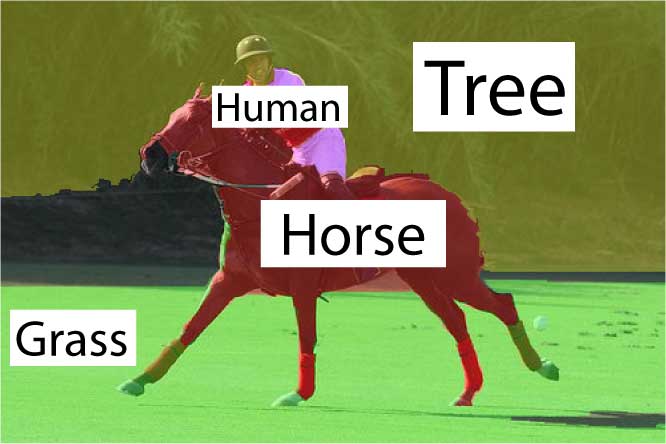
The comparison between the results in the first two columns underscores the effectiveness of the contextual facilitation by the top-down classification on the annotation and segmentation tasks. |
||||||||||||||||||||||||||||
Resources back to top |
||||||||||||||||||||||||||||
[1] Li-Jia Li, Richard Socher and Li Fei-Fei. Towards Total Scene Understanding:Classification, Annotation and Segmentation in an Automatic Framework. Computer Vision and Pattern Recognition (CVPR) 2009. PDF |
||||||||||||||||||||||||||||
Selected References back to top |
||||||||||||||||||||||||||||
[2] Li-Jia Li and Li Fei-Fei. What, where and who? Classifying event by scene and object recognition . IEEE Intern. Conf. in Computer Vision (ICCV). 2007. PDF [3] Li Fei-Fei and Pietro Perona. A Bayesian hierarchy model for learning natural scene categories. Computer Vision and Pattern Recognition (CVPR), 2005. [4] Liangliang Cao and Li Fei-Fei. Spatially coherent latent topic model for concurrent object segmentation and classification. IEEE Intern. Conf. in Computer Vision (ICCV). 2007. [5] David Blei and Micheal Jordan. Modeling annotated data. ACM SIGIR Conference on Research and Development in Information Retrieval, 2003. |
||||||||||||||||||||||||||||
Last modified April 2009 by Li-Jia Li |
||||||||||||||||||||||||||||