Stanford Dogs Dataset
Aditya Khosla Nityananda Jayadevaprakash Bangpeng Yao Li Fei-Fei
Stanford University
The Stanford Dogs dataset contains images of 120 breeds of dogs from around the world. This dataset has been built using images and annotation from ImageNet for the task of fine-grained image categorization. Contents of this dataset:
- Number of categories: 120
- Number of images: 20,580
- Annotations: Class labels, Bounding boxes
Download
You can download the dataset using the links below:
- Images (757MB)
- Annotations (21MB)
- Lists, with train/test splits (0.5MB)
- Train Features (1.2GB), Test Features (850MB)
- README
Dataset Reference
Primary:
Aditya Khosla, Nityananda Jayadevaprakash, Bangpeng Yao and Li Fei-Fei. Novel dataset for Fine-Grained Image Categorization. First Workshop on Fine-Grained Visual Categorization (FGVC), IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2011. [pdf] [poster] [BibTex]
Secondary:
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li and L. Fei-Fei, ImageNet: A Large-Scale Hierarchical Image Database. IEEE Computer Vision and Pattern Recognition (CVPR), 2009. [pdf] [BibTex]
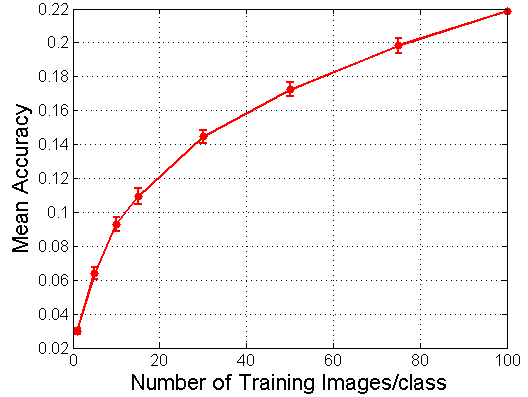 Baseline Results
Baseline Results This section contains baseline results on two tasks:
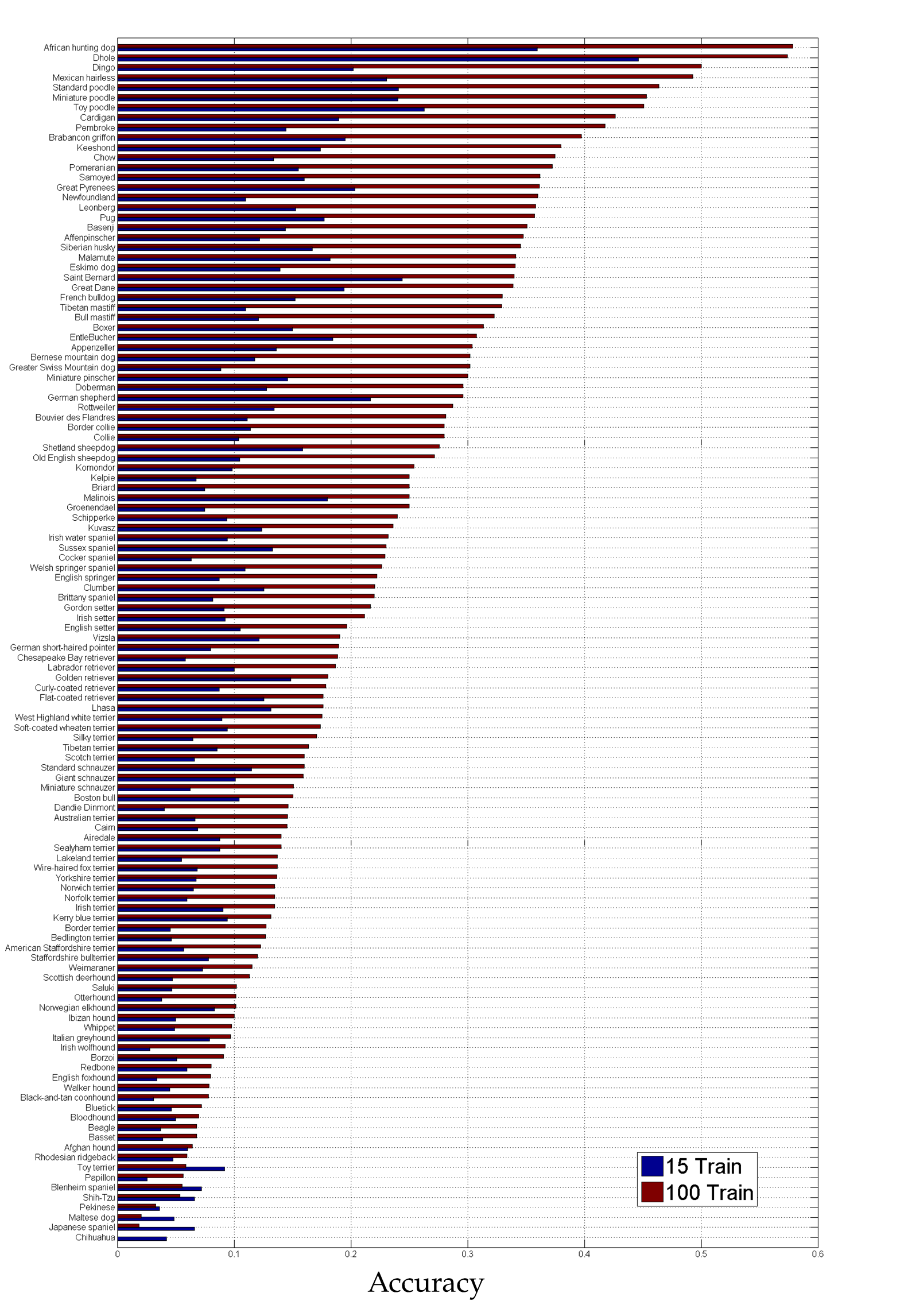
Experimental Setting All of the experiments use image regions from the bounding box only for both training and testing. The remaining parameters are set to the following values:
Contact: aditya86@cs.stanford.edu bangpeng@cs.stanford.edu |