A Multi-View Probabilistic Model for 3D Object Classes
Min Sun1* Hao Su1,3* Silvio Savarese2 Li Fei-Fei1
1Dept. of Computer Science, Princeton University, NJ 08540, USA
2Dept. of Electrical and Computer Engineering, University of Michigan at Ann Arbor, MI 48109, USA
3Dept. of Computer Science, Beihang University, China
Summary
We propose a novel probabilistic framework for learning visual models of 3D object categories by combining appearance information and geometric constraints. Objects are represented as a coherent ensemble of parts that are consistent under 3D viewpoint transformations. Each part is a collection of salient image features. A generative framework is used for learning a model that captures the relative position of parts within each of the discretized viewpoints. Contrary to most of the existing mixture of viewpoints models, our model establishes explicit correspondences of parts across different viewpoints of the object class. Given a new image, detection and classification are achieved by determining the position and viewpoint of the model that maximize recognition scores of the candidate objects. Our approach is among the first to propose a generative probabilistic framework for 3D object categorization. We test our algorithm on the detection task and the viewpoint classification task by using “car” category from both the Savarese et al. 2007 and PASCAL VOC 2006 datasets. We show promising results in both the detection and viewpoint classification tasks on these two challenging datasets.
Model Overview
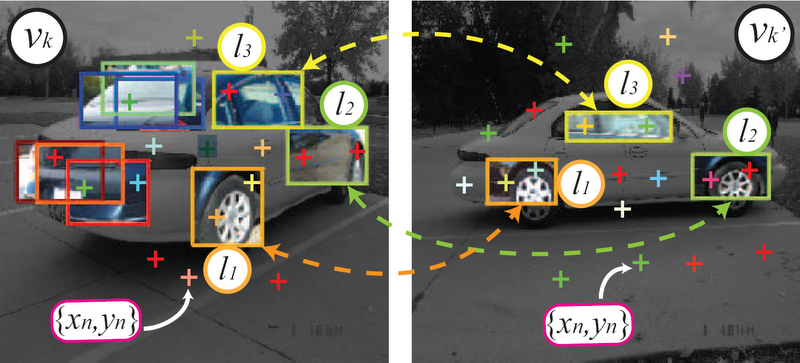
Generation process of two particular viewpoints of a car. v is the viewpoint index of the object. Given a pair of images from nearby viewpoints, part types assignment l (color coded boxes) are sampled from the viewpoint specific spatial configuration and enforced to satisfy the part correspondences constraints (dashed arrows). Feature (colored crosses) positions and codewords are sampled given each part l and viewpoint v.

Viewpoint images generated from our learned 3D object model for the car category. Each image shows a mixture of randomly sampled parts as well as their geometric configurations from the learned model, superimposed on an image of a car in this viewpoint. The fully trained car category model consists of 18 parts across all 32 discretized viewpoints on the full viewing sphere of the object class. Each part is represented by a color coded bounding box. Contrary to most of the mixture of viewpoints object models, the learned parts in our model are maintained across different viewpoints. This figure is best viewed in color under PDF magnification.
Evaluation
We evaluate our algorithm on the detection task and the viewpoint classification task by using “car” category from both the Savarese et al. 2007[1] and PASCAL VOC 2006[2] datasets.
Detection and viewpoint classification results using the Savarese et al. dataset are shown below:
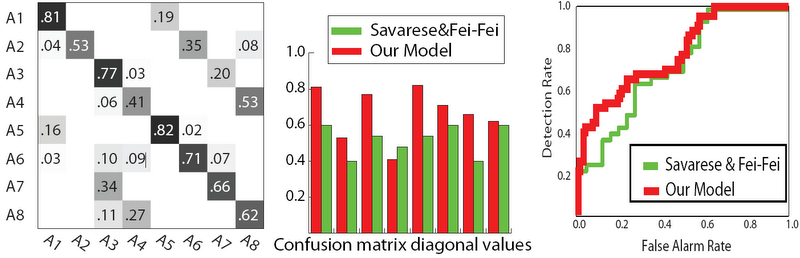
Left: confusion matrix of the viewpoint classification. Center: diagonal element of our average confusion matrix (red) compared with the one from [1] (green). Right: binary object classification and detection result (ROC) (red) compared with the one from [1]
Detection and viewpoint classification results using the PASCAL VOC 2006 datasets are shown below:
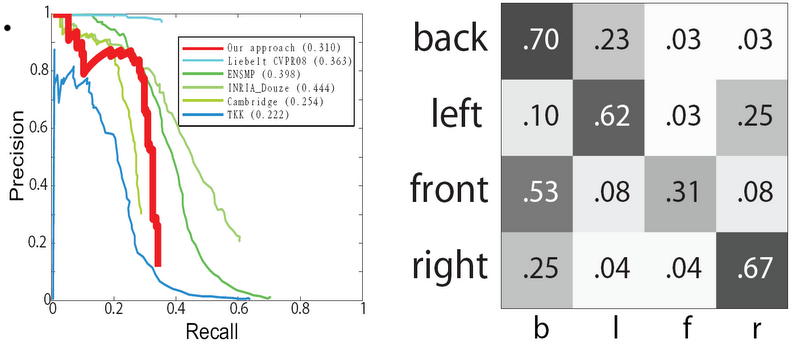
(a) Detection results measured in precision-recall curve of our model (red) compared to [3] and the detection result of the PASCAL VOC 2006 challenge [2]- INRIA Douze , [2]-INRIA Laptev, [2]-TKK, [2]-Cambridge, and [2]-ENSMP. Average precision (AP) scores are shown in the legends. (b) Confusion table of the four viewpoint classification task. The average performance is 62% across the diagonal of the confusion.
Example Results
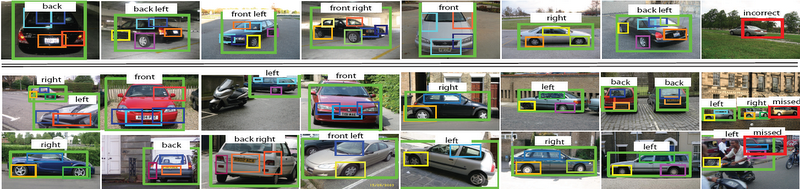
Sample viewpoint classification results. Proposed object detections are indicated by green bounding boxes. Text labels show the predicted viewpoints. Smaller rectangles illustrate the supporting parts learned before part expansion. The top row shows results from the [1] dataset; and the bottom 2 rows show results from the PASCAL VOC 2006 dataset. The last column shows examples of missed or incorrect detections.
Resources
- *M. Sun, *H. Su, S. Savarese and L.
Fei-Fei. A Multi-View Probabilistic Model for 3D Object Classes. To
appear in Computer Vision and Pattern Recognition (CVPR) 2009.
(*indicates equal contributions)
Fulltext PDF
Selected References
- S. Savarese and L. Fei-Fei. 3D generic object categorization,
localization and pose estimation. IEEE Intern. Conf. in Computer Vision
(ICCV). 2007.
Fulltext PDF - M. Everingham, A. Zisserman, C.
Williams, and L. V. Gool. The PASCAL Visual Object Classes Challenge
2006 Results. Technical Report, PASCAL Network, 2006.
Challenge sitehttp://pascallin.ecs.soton.ac.uk/challenges/VOC/voc2006/index.html - J. Liebelt, C. Schmid, and K. Schertler. Viewpoint-independent object class detection using 3d feature maps. CVPR, June 2008.
Author sitehttp://lear.inrialpes.fr/~schmid/