Summary
We propose a fully automatic framework to detect and extract arbitrary human motion volumes from real-world videos collected from YouTube. Our system is composed of two stages. A person detector is first applied to provide crude information about the possible locations of humans. Then a constrained clustering algorithm groups the detections and rejects false positives based on the appearance similarity and spatio-temporal coherence. In the second stage, we apply a top-down pictorial structure model to complete the extraction of the humans in arbitrary motion. During this procedure, a density propagation technique based on a mixture of Gaussians is employed to propagate temporal information in a principled way. This method reduces greatly the search space for the measurement in the inference stage. We demonstrate the initial success of this framework both quantitatively and qualitatively by using a number of YouTube videos.
System overview

Evaluation
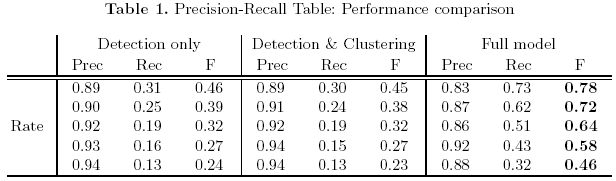
We evaluate the retrieval performance of our system in terms of the precision-recall measures. For each sequence, we have generated ground-truth by manually labeling every human present in each frame with a bounding box. We compare the precision-recall rates at three stages of our system: pedestrian detection only, people detection and clustering, and the full model. For a fixed threshold of the human detector, we obtain the three precision-recall pairs in each row of Table 1. Our full system provides the highest performance in terms of the F- measure. This reflects the fact that our system achieves much higher recall rates by extracting non-upright people beyond the pedestrian detections.
Example Results


 demo1 |


 demo2 |


 demo3 |


 demo4 |


 demo5 |


 demo6 |


 demo7 |


 demo8 |


 demo9 |


 demo10 |
Dataset
The dataset used in our experiments contains 50 sequences with variuos human motion types. You may download the data here:
Dataset (1.5GB) (release date:
september 05, 2008)